Pandas的详细笔记
Pandas简介
应用
Pandas 可以对各种数据进行运算操作,比如归并、再成形、选择,还有数据清洗和数据加工特征。广泛应用在学术、金融、统计学等各个数据分析领域。
对象
Series(一维数据):由一组数据和一组对应的数据标签(索引)组成。
DataFrame(二维数据):表格类型,既有行索引也有列索引。
Pandas使用
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
import pandas as pd
pd._version_#查看pandas版本
mydataest = {
'sites':['Google','Runoob','wiki'],
'number':[1,2,3]
}
myvar = pd.DataFrame(mydataset)
print(myvar)
|
结果如下:
|
sites |
number |
| 0 |
google |
1 |
| 1 |
Runoob |
2 |
| 2 |
Wiki |
3 |
Pandas数据结构 - Series
Series类似于表格中的列:
pandas.Series(data,index,dtype,name,copy)
其中index为数据索引标签,默认从0,其中,索引值也可以自己规定:
1
2
3
4
5
6
7
| import pandas as pd
a = ["Google", "Runoob", "Wiki"]
myvar = pd.Series(a, index = ["x", "y", "z"])
print(myvar)
|
我们同样可以使用字典类型来创建Series:
1
2
3
4
5
6
7
| import pandas as pd
sites = {1: "Google", 2: "Runoob", 3: "Wiki"}
myvar = pd.Series(sites)
print(myvar)
|
其中name用来给当前表格命名
Pandas数据结构 - DataFrame
DataFrame可以看做共用一个索引的多个Series:
pandas.DataFrame( data, index, columns, dtype, copy)
其中index表示行标签,columns表示列标签。
DataFrame的创建
1
2
3
4
5
6
7
| import pandas as pd
data = [['Google',10],['Runoob',12],['Wiki',13]]
df = pd.DataFrame(data,columns = ['Site','Age'],dtype = float)
print(df)
|
结果如下:
|
Site |
Age |
| 0 |
google |
10.0 |
| 1 |
Runoob |
12.0 |
| 2 |
Wiki |
13.0 |
- 我们当然也可以使用ndarrays进行创建,如下:
1
2
3
4
5
6
7
| import pandas as pd
data = {'Site':['Google', 'Runoob', 'Wiki'], 'Age':[10, 12, 13]}
df = pd.DataFrame(data)
print (df)
|
1
2
3
4
5
6
7
| import pandas as pd
data = [{'a': 1, 'b': 2},{'a': 5, 'b': 10, 'c': 20}]
df = pd.DataFrame(data)
print (df)
|
其中输出结果c对应的第一行结果为NaN表示没有对应数据
Dataframe的索引
我们利用loc属性进行索引:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| import pandas as pd
data = {
"calories": [420, 380, 390],
"duration": [50, 40, 45]
}
# 数据载入到 DataFrame 对象
df = pd.DataFrame(data)
# 返回第一行
print(df.loc[0])
# 返回第二行
print(df.loc[1])
# 返回第一行和第二行
print(df.loc[[0, 1]])
# 返回第一行和第二行的第一列
print(df.iloc[[0,1],[0]])
|
其中注意loc是根据index的名称或者数字来定义,iloc则是单纯根据排序。
Pandas读取CSV
yourtest.csv需要预先放在工作目录下。
1
2
3
4
5
6
7
| import pandas as pd
df = pd.read_csv('yourtest.csv')
print(df.to_string())
#to_string用于返回 DataFrame 类型的数据,如果不使用该函数,则输出结果为数据的前面 5 行和末尾 5 行,中间部分以 ... 代替。
print(df)
|
我们也可以使用 to_csv() 方法将 DataFrame 存储为 csv 文件:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| import pandas as pd
# 三个字段 name, site, age
nme = ["Google", "Runoob", "Taobao", "Wiki"]
st = ["www.google.com", "www.runoob.com", "www.taobao.com", "www.wikipedia.org"]
ag = [90, 40, 80, 98]
# 字典
dict = {'name': nme, 'site': st, 'age': ag}
df = pd.DataFrame(dict)
# 保存 dataframe
df.to_csv('site.csv')
|
其他数据处理方法
- head(n):查看前n行数据,不填则默认5行。
- tail(n):尾部5行。
- info():返回部分信息。
Pandas和Json
关于相关内容需要了解Json相关,在后文再做讨论。
Pandas 数据清洗
对如下数据:
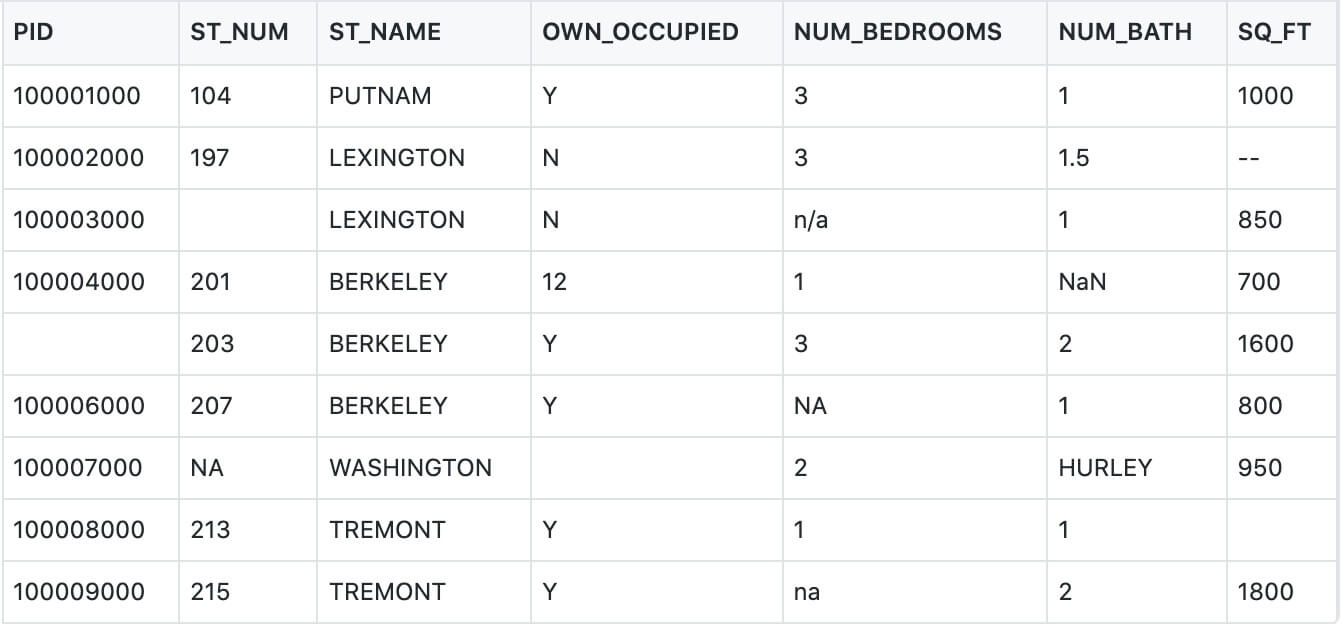 包含如下四种空数据:
包含如下四种空数据:
- n/a
- NA
-
- na
清洗空值
DataFrame.dropna(axis=0, how=‘any’, thresh=None, subset=None, inplace=False)
- axis:默认为 0,表示逢空值剔除整行,如果设置参数 axis=1 表示逢空值去掉整列。
- how:默认为 ‘any’ 如果一行(或一列)里任何一个数据有出现 NA 就去掉整行,如果设how=‘all’ 一行(或列)都是 NA 才去掉这整行。
- thresh:设置需要多少非空值的数据才可以保留下来的。
- subset:设置想要检查的列。如果是多个列,可以使用列名的 list 作为参数。
- inplace:如果设置 True,将计算得到的值直接覆盖之前的值并返回 None,修改的是源数据。
不一定需要全部写全参数,不加进去就不会默认执行。比如axis就不应该加,就不会一定删除某一行一列。
我们通过isnull()来判断单元格是否为空:
print (df[‘NUM_BEDROOMS’].isnull())
除此之外,我们可以指定空数据类型,比如Pandas只认为n/a,和NA为空数据,对于中文‘无’:
1
2
3
4
5
6
7
| import pandas as pd
missing_values = ["n/a", "na", "--",'无']
df = pd.read_csv('property-data.csv', na_values = missing_values)
print (df['NUM_BEDROOMS'])
print (df['NUM_BEDROOMS'].isnull())
|
一般清洗之后不会修改源数据,如果想修改,请把inplace改为True。
替换空字段
1
2
| df.fillna(12345,inplace = True)#替换全部空处
df['somecolumn'].fillna(12345, inplace = True)#替换指定列
|
通过插值替换空单元格:均值,中位数,众数。
1
2
3
| x = df["ST_NUM"].mean()#以均值为例,其余median,mode类似。
df["ST_NUM"].fillna(x, inplace = True)
|
Pandas 清洗错误格式数据
1
2
3
4
5
6
7
8
9
10
11
12
13
| import pandas as pd
# 第三个日期格式错误
data = {
"Date": ['2020/12/01', '2020/12/02' , '20201226'],
"duration": [50, 40, 45]
}
df = pd.DataFrame(data, index = ["day1", "day2", "day3"])
df['Date'] = pd.to_datetime(df['Date'])
print(df.to_string())
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| import pandas as pd
person = {
"name": ['Google', 'Runoob' , 'Taobao'],
"age": [50, 200, 12345]
}
df = pd.DataFrame(person)
for x in df.index:
if df.loc[x, "age"] > 120:
df.loc[x, "age"] = 120#df.drop(x, inplace = True)可以将其删除
print(df.to_string())
|
Pandas 清洗重复数据
使用duplicated()和drop_duplicates()
1
2
3
4
5
6
7
8
9
10
11
12
| import pandas as pd
person = {
"name": ['Google', 'Runoob', 'Runoob', 'Taobao'],
"age": [50, 40, 40, 23]
}
df = pd.DataFrame(person)
df.drop_duplicates(inplace = True)
print(df.duplicated())#返回bool值
print(df)#返回删除后的表格
|






