
Pytorch学习
请一定给自己一个足够说服你行动的理由。
在开始我的分享之前,我想回答几个自问自答的问题:
-
为什么要用网站分享,而不是PPT? 答:这个问题我思考了很久,因为不使用PPT进行分享是不合常理的,甚至是对老师和同学不尊重的行为,但思考了很久之后我认为这个网站的存在是永久的,易于你在随时随地查看这些内容,甚至你在工作的时候需要查看某项函数的时候都可以点开看。从实用性来看,我坚持使用网站进行分享。
-
你的分享逻辑和原则是什么? 答:你可以通过网页右侧的目录来查看我的分享大纲,其中有些部分不适合展开细讲的,我都会给出一个链接适合有需要的同学点开钻研。
我的大致分享思路如下:
- 介绍conda
- 介绍Jupyter
- 介绍Pandas,Numpy,Matplotlib
- 预备知识的回顾
- 预备知识的继续
介绍conda
Conda是一个管理版本和Python环境的工具,它使用起来非常容易。
Conda包安装之后,需要添加环境变量才可以在命令行里调用。
- 为什么要配置环境变量?
根据Windows系统在查找可执行程序的原理,只会从当前文件夹下执行目标文件(比如SDK中的解释器,用于语言的编译),因此只有加上环境变量,就能让操作系统方便在任何目录下都能执行目标文件。 -来自CSDN博主一夜星尘
关于环境变量的详细配置在这里
- conda 创建环境
1 | # 创建一个名为miaomiao的环境,指定Python版本是3.5 |
- conda 激活环境
1 | activate miaomiao |
- conda 删除环境
1 | conda remove --name miaomiao --all |
- conda 查看系统中所有的环境
1 | conda info -e |
Anaconda是一个免费、易于安装的包管理器、环境管理器(包含conda)和Python发行版。包含1,500多个开源包,并提供免费社区支持。
关于更详尽的conda介绍在这里
介绍Jupyter
Jupyter Notebook是基于网页的用于交互计算的应用程序。其可被应用于全过程计算:开发、文档编写、运行代码和展示结果。——Jupyter Notebook官方介绍
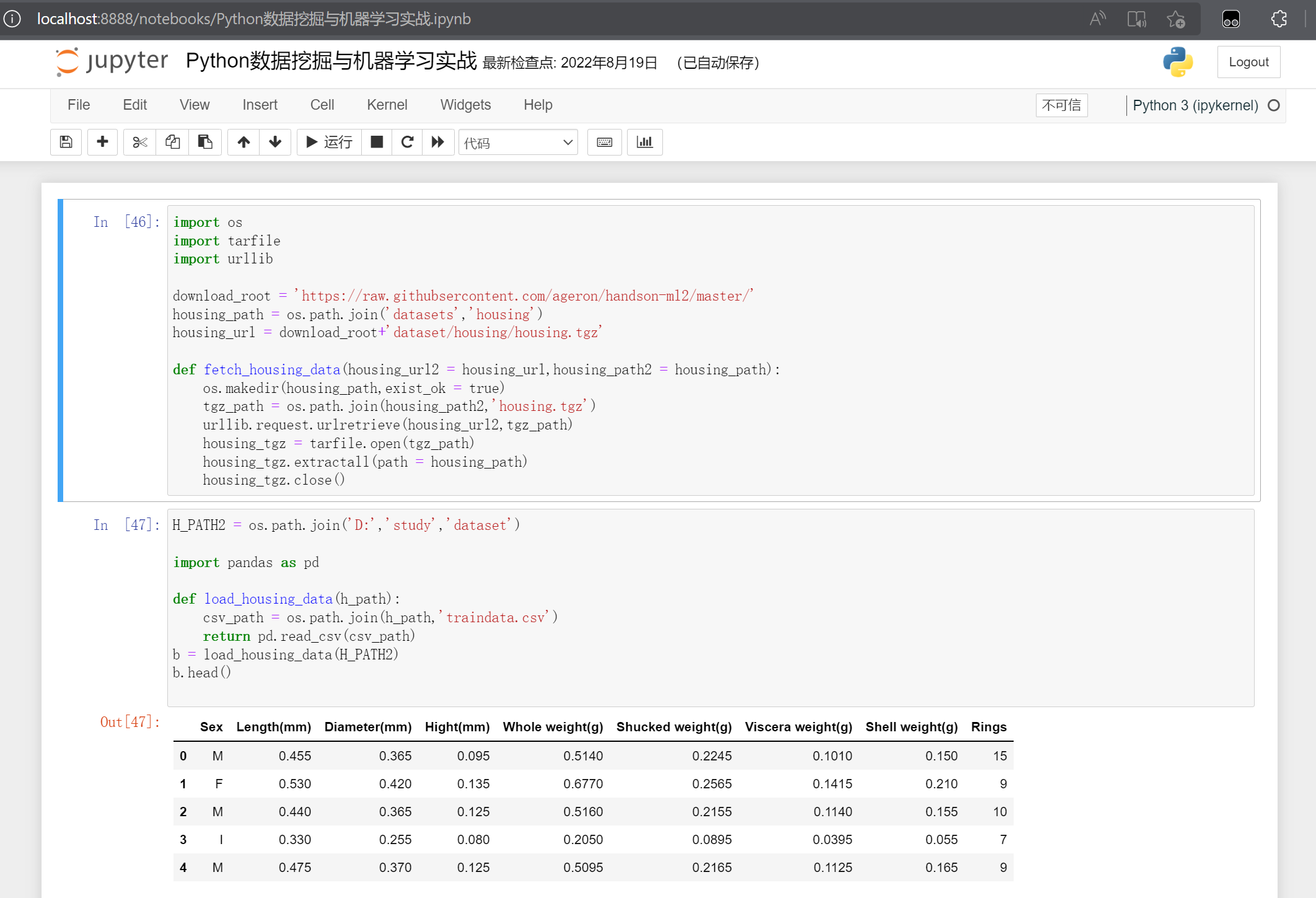
-Jupyter的操作页面
Jupyter Notebook以网页的形式打开,可以在网页页面中直接编写代码和运行代码,代码的运行结果也会直接在代码块下显示的程序。如在编程过程中需要编写说明文档,可在同一个页面中直接编写,便于作及时的说明和解释。

-Jupyter的部分贡献者
Jupyter由网页应用和文档两部分组成,其中每一行代码都可以单独给出结果,适合于进行代码的学习和授课。
Jupyter的基本操作
事实上,我们在Jupyter上的很多操作都是利用快捷键完成的。常用的快捷键如下:
-常用的Jupyter操作快捷键
我们可以使用os包来查看当前工作的目录
1 | import os |
完整版可以在Jupyter的操作页面的Help–Keyboard Shortcuts中找到。
如何在Jupyter Notebook中使用Python虚拟环境
Python虚拟环境的出现是因为Python目前有两个版本共存。
虽然Python 3有许多优于Python 2的特性,但是Python 2的生态系统更为完善,支持的包更多。因为生态系统内部的依赖关系,许多软件包的运行说明会直接指定“仅适用于Python 2.7版本”。
我们可以很容易的在电脑里建立起多个虚拟环境,利用conda即可完成,但是在这里建立的环境并不适用于Jupyter,为了让Jupyter Notebook支持虚拟运行环境,需要在Anaconda里安装一个插件。
他的名字叫做:ipykernel
1 | conda create --name miaomiao python=3.9 |
之后我们点开任意文档都可以在kernel中切换成该环境。
我们可以直接使用anconda进行安装和使用,其中默认的环境是base,我们可以手动更改环境。
关于更详尽的Jupyter介绍在这里
简单介绍Pandas和Numpy,Matplotlib
- Numpy是Python语言的一个扩展程序库,支持大量的维度数组与矩阵运算,此外也针对数组运算提供大量的数学函数库。最重要的一个特点是其 N 维数组对象ndarray,它是一系列同类型数据的集合,以0下标为开始进行集合中元素的索引。其ndarray与torch有相似之处且可以互相转化,torch被誉为神经网络界的numpy,torch本身利用GPU(图形处理器)进行加速,numpy则是利用CPU(中央处理器)进行加速。
- Pandas也是Python语言的一个扩展程序库,是基于numpy的强大的分析结构化数据的工具集。主要数据结构是Series(一维数据)与DataFrame(二维数据)。
- Matplotlib是Python的绘图库。
以上拓展库都可以使用pip(推荐)或者conda进行安装。
预备知识
数据操作
数据操作的基础:
- 获取和存储数据
- 处理数据
我们使用tensor(张量)进行操作,其类似于Numpy中的ndarray,但由于GPU加速计算和一些额外的重要功能使得tensor更适合深度学习。
那么为什么机器学习要使用GPU进行加速呢?GPU和CPU的区别在哪里?
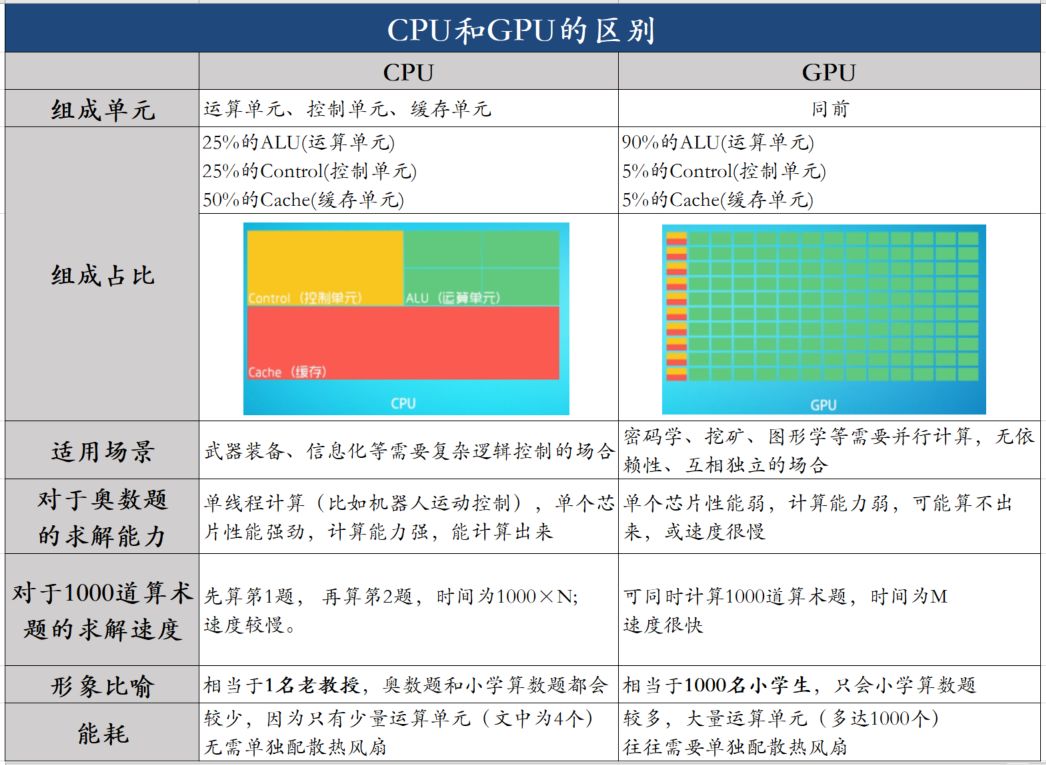
-
GPU与CPU的区别 关于更详尽的介绍在这里
-
安装深度学习框架和d2l软件包 使用pip或conda安装PyTorch的CPU或GPU版本:
1 | pip install torch |
然后安装d2l包,以方便调取机器学习中常用的函数和类:
1 | pip install d2l |
入门
在此用例子来复习一些tensor的基本用法:
1 | import torch |
在此需要注意,在numpy和torch创建列表的区别,两者都可以使用np.zeros()或者torch.zeros()创建空列表,但是np必须加上[],例如
np.zeros([1,2,3])
但是np.zeros(1,2,3)就会报错。
而torch则兼容,建议在日常中使用[]。
运算符
1 | x = torch.tensor([1.0, 2, 4, 8]) |
除按照元素计算,我们还可以以执行线性代数运算,包括向量点积和矩阵乘法。
如下介绍张量连接:
1 | X = torch.arange(12, dtype=torch.float32).reshape((3,4)) |
dim=0按照轴0,即行进行连接,dim=1按照轴1,即列连接。
X.sum()表示求和
广播机制
在张量形状不同的情况下,我们仍然可以通过调用广播机制(broadcasting mechanism)来执行按元素操作:
1 | a = torch.arange(3).reshape((3, 1)) |
需要注意的是,广播机制的扩展是有一定规律的,其详细的广播机制可以在这个网站里找到。
其大致方式为:
- 比较两个数组从后往前,维度是否相等或者为1。否则无法广播。
- 若为1,则扩展到相同的维度,以此依次进行,直到维度相等。
索引
在前面已经提过
内存节省
Y = X + Y
1 | before = id(kitty) |
我们使用切片表示来将操作结果分配给先前数组:
1 | Z = torch.zeros_like(Y) |
转换为其他python对象
深度学习中,我们使用定义的张量可以转化为Numpy中的ndarray,并且共享同一个内存(部分共享)。会同时被更改:
1 | A = X.numpy() |
其实我们也可以从numpy中创建tensor,利用torch.from_numpy进行创建:
1 | ndarray1 = np.array([[1,2,3],[4,5,6]]) |
数据预处理
我们使用pandas包(与tensor兼容)进行数据的原始预处理:
读取数据集
我们利用os包进行操作:
1 | import os |
处理缺失值
我们在此考虑插值法处理缺失值。 通过位置索引iloc,我们将data分成inputs和outputs,其中前者为data的前两列,⽽后者为data的最后一列。对于inputs中缺少的数值,我们用同一列的均值替换“NaN”项。
1 | inputs, outputs = data.iloc[:, 0:2], data.iloc[:, 2] |
结果如下:
| NumRooms | Alley | |
|---|---|---|
| 0 | 3.0 | Pave |
| 1 | 2.0 | NaN |
| 2 | 4.0 | NaN |
| 3 | 3.0 | NaN |
由于“巷子类型”(“Alley”)列只有两种类型的类别值“Pave”和“NaN”,pandas自动将此列转换为两列“Alley_Pave”和“Alley_nan”。
巷子类型为“Pave”的行会将“Alley_Pave”的值设置为1,“Alley_nan”的值设置为0。
缺少巷子类型的行会将“Alley_Pave”和“Alley_nan”分别设置为0和1。
1 | inputs = pd.get_dummies(inputs, dummy_na=True) |
| NumRooms | Alley_Pave | Alley_nan | |
|---|---|---|---|
| 0 | 3.0 | 1 | 0 |
| 1 | 2.0 | 0 | 1 |
| 2 | 4.0 | 0 | 1 |
| 3 | 3.0 | 0 | 1 |




